Google TurboQuant, AI 메모리 6배 압축...메모리칩 주가 '급락'
Google이 3월 발표한 TurboQuant 알고리즘은 AI의 KV 캐시 메모리를 6배 압축하면서도 성능 손실이 없다. 추론 속도는 최대 8배 향상되며 추가 학습 없이 기존 모델에 바로 적용 가능하다. 발표 직후 메모리칩 주가가 급락하며 반도체 시장에 충격을 주고 있다.

Google TurboQuant, AI 메모리 6배 압축...메모리칩 주가 '급락'
Google 연구팀이 지난 3월 24일 공개한 차세대 인공지능(AI) 메모리 압축 알고리즘 'TurboQuant'가 글로벌 반도체 시장을 흔들고 있다. 16비트(32비트) 정밀도로 처리하던 AI 모델의 주요 메모리인 KV(Key-Value) 캐시를 단 3비트로 줄이면서 성능 손실이 전혀 없다는 것이 핵심이다.
숫자로 보는 TurboQuant의 충격
Google TurboQuant는 KV 캐시 메모리 크기를 6배 이상 줄이면서 모든 테스트에서 완벽한 다운스트림 결과를 달성했다. 추가 학습 없이 기존 모델에 바로 적용할 수 있다. 4비트 TurboQuant는 Nvidia H100 가속기에서 32비트 미압축 키 대비 주의력(Attention) 로짓 계산 속도를 8배 향상시켰다.
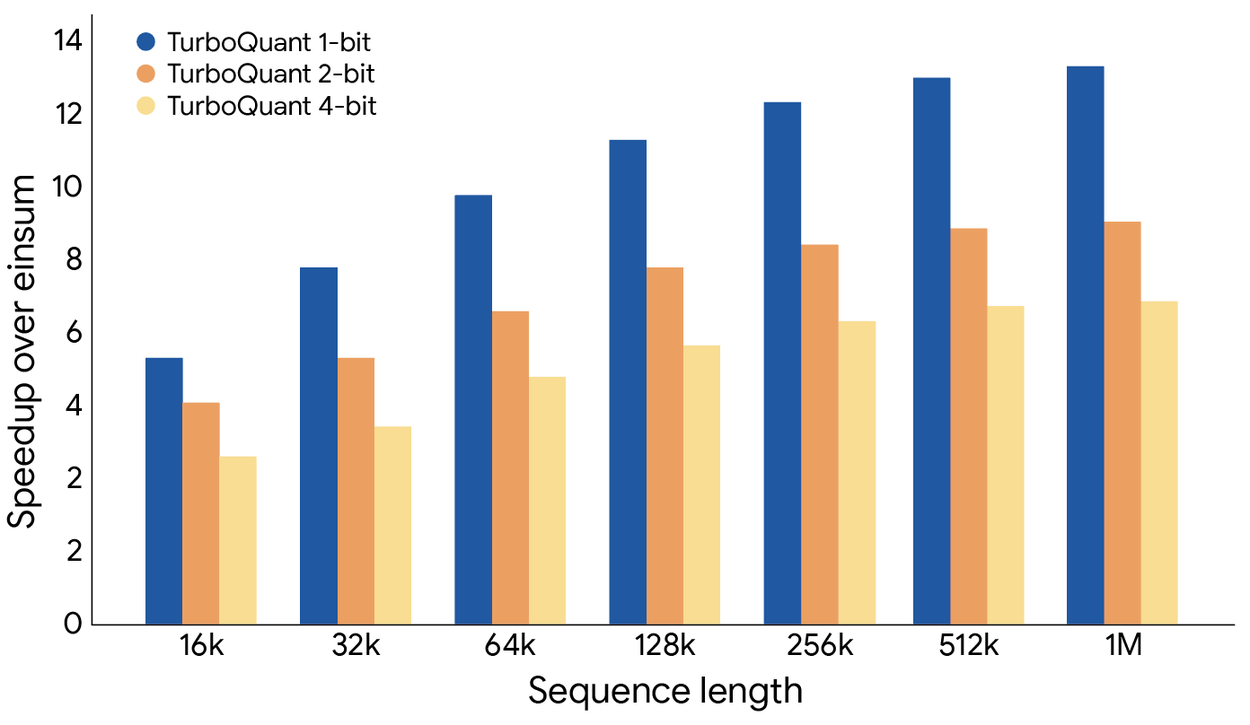
시장의 반응은 즉각적이었다. TurboQuant 발표 이후 메모리 공급업체인 Micron과 Western Digital 등의 주가가 하락세를 보였다. 시장은 AI 업체들이 소프트웨어만으로 메모리 수요를 6분의 1로 줄일 수 있다면, 고대역폭 메모리(HBM)에 대한 왕성한 수요가 완화될 수 있다는 판단을 했다.
이는 AI 데이터센터의 메모리 구매량 급증을 기대한 투자자들에겐 '청천벽력'과 같은 소식이었다. 메모리 칩 제조업체들이 패닉에 빠졌고, PC 빌더들은 일제히 "이제 메모리 가격이 내려갈 수 있나?"라는 질문을 던졌다.
기술의 본질: '극단적 효율화'의 시대
TurboQuant의 작동 원리는 두 단계로 이루어진다. 첫 번째로 PolarQuant라 불리는 방식이 사용된다. 기존의 XYZ 직교좌표 대신 극좌표(Polar Coordinate)로 벡터를 변환하는데, 이는 "동쪽으로 3블록, 북쪽으로 4블록"을 "총 5블록, 37도 각도"로 표현하는 것과 같다. QJL은 Johnson-Lindenstrauss 변환을 사용해 고차원 데이터를 축소하면서 데이터 포인트 간 본질적 거리와 관계를 보존하며, 각 벡터 숫자를 단일 부호 비트(+1 또는 -1)로 축소한다.
핵심은 '무손실 압축'이라는 점이다. Google은 모델 재학습이나 캘리브레이션 데이터 없이, 측정 가능한 출력 품질 변화 없이 메모리 사용량을 최소 6배 줄일 수 있다고 발표했다. 이는 업계 상식을 뒤엎는 성과다. 지난해 중국의 DeepSeek이 저비용 학습으로 AI 모델링의 지형도를 바꿨다면, 이번엔 '추론 효율성'에서의 게임 체인저가 나타난 셈이다.
누가 가장 큰 피해를 입나?
TurboQuant는 AI 모델의 단기 메모리인 KV 캐시를 압축하여 저장 및 전송 데이터량을 줄인다. 기술은 KV 캐시 사용량을 6분의 1로 줄이면서도 원래 수준에 가까운 정확성을 유지하며, Nvidia H100 GPU에서 8배 추론 속도 향상을 달성한다.
이 기술이 광범위하게 도입되면 데이터센터의 전력 소비와 운영 비용이 획기적으로 낮아질 수 있다. AI 거대 기업들이 소프트웨어만으로 메모리 수요를 6분의 1로 줄일 수 있다면, 고대역폭 메모리(HBM)에 대한 왕성한 수요가 완화될 것이라는 판단이 가장 큰 영향을 미쳤다. 이는 업계가 "더 큰 모델"에서 "더 효율적인 메모리"로 초점을 옮긴다는 신호다.
하지만 일부 전문가는 장기적 영향을 재평가하고 있다. KAIST 교수는 "메모리 수요는 계속 증가할 것이고, 이런 기술들이 성장 속도를 늦출 순 있지만 방향을 바꾸진 못할 것"이라며, KV 캐시 사용량이 AI 진화와 구조적으로 연결돼 있어 모델이 더 긴 맥락을 처리할수록 메모리 수요도 함께 증가할 수밖에 없다고 지적했다.
한국 반도체 산업의 숨은 의미
국내 메모리 반도체 업계에도 변수가 생겼다. SK하이닉스와 삼성전자는 과거 몇 년간 AI 메모리 고수요에 베팅했는데, TurboQuant 같은 효율화 기술이 시장을 재편할 수 있기 때문이다. AI 운영 비용이 50% 이상 떨어질 수 있다는 분석이 나온 만큼, 장기적으로는 조직의 고대역폭 메모리(HBM) 중심 하드웨어 조달 계획을 재검토하게 될 것이다. 동시에 온프레미스 또는 엣지 디바이스에서 고성능 AI 모델을 실행할 수 있게 되면서 프라이빗 AI 인프라 수요가 증가할 가능성도 있다.
결론: 효율성 경쟁의 시작
브루트포스(무차별적 규모 확대) 방식의 AI 스케일링 시대가 지나가고 있다. 이제 최고 연구팀들은 모델 크기와 성능뿐 아니라 효율성과 비용에서도 경쟁하고 있다는 신호다. 업계 전체로 보면 이는 긍정적이다. 더 효율적인 AI는 더 많은 기업이 접근할 수 있게 하고 지속 가능한 성장을 주도한다.
Google이 TurboQuant를 개방 연구 프레임워크 하에 공개하기로 결정한 이유도 명확하다. 에이전틱 AI 시대를 맞아 대규모의 효율적이고 검색 가능한 벡터화 메모리가 필수 인프라가 됐기 때문이다. Q2 2026 중 예상되는 오픈소스 코드 공개를 앞두고, 벤더 로크인 없는 공개 표준의 중요성이 더욱 부각되고 있다.
원문 출처
- https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/
- https://techcrunch.com/2026/03/25/google-turboquant-ai-memory-compression-silicon-valley-pied-piper/
- https://venturebeat.com/infrastructure/googles-new-turboquant-algorithm-speeds-up-ai-memory-8x-cutting-costs-by-50/
편집 안내 | 이 기사는 AI 기술을 활용하여 글로벌 뉴스 소스를 분석·종합한 후, AIB프레스 편집팀의 검수를 거쳐 발행되었습니다. 정확한 정보 전달을 위해 노력하고 있으며, 원문 출처를 함께 제공합니다.
AI·테크 핵심 뉴스, 매주 한 통으로
한 주의 글로벌 AI·IT 뉴스 중 꼭 알아야 할 것만 골라 보내드립니다. 광고 없음, 언제든 해지.